
The library cafe analogy
by Peter Small
The ideas, for an organic system that can be used to enhance collaborative activity in the search for information on the Internet, first surfaced in the book "Magical A-Life Avatars" by Peter Small (Manning 1998). In this book (chapter 6, page 178), the situation was described as follows:
From "Magical A-Life Avatars" chapter 6, page 178
Looking at the Internet from a conventional mass media perspective, the Web has the potential to supply us with all the information we could ever possibly need. The Internet would seem to allow us to contact millions of others, to seek their advice or ask for assistance. We can read news group postings on thousands of different subjects, we can belong to any number of special interest groups to discuss with our peers the intricate details of any arcane subject under the sun. It would all seem to add up to an apparent information Utopia...
...that is, until you start to apply a little common sense.
The problem is that there are just too many people to communicate with on the Internet. There is simply too much stuff on the World Wide Web. It's like looking into a fractal: the more you look the more you find to see. The stark reality is that however useful or entertaining you find the Internet, there is a limited, finite amount of time available to devote to it. Even the most obsessive user can only sample a small fraction of the total available material. Time prevents anyone from subscribing actively to more than a handful of special interest list serves (SIGs) or newsgroups. Even with the aid of powerful search engines the retrieval of specific information is often time consuming and frustratingly inconclusive. How then, can we cope with the information overload which stymies the efficient use of what could become an all powerful source of information?
The trick is to abstract out from this setting the main elements of the problem. Once you have the main elements, you can then put them into a less complicated model of the situation, to see if any solutions present themselves. In this case the main elements are: 1) too much information and; 2) limited time available.
Too much information can be represented by imagining a library which contains every book and document ever written in the world. To make the model conform more to the way the Internet is arranged, you can think of all the books and documents as being placed in the library in an unordered way: millions and millions of books, magazines, newspapers and papers just piled up anywhere. To make it even more like the World Wide Web, there can be armies of people arriving every day with fresh assortments of books, magazines and documents which are randomly distributed around the shelves with other people spending their time moving stuff around and taking stuff away.
Introducing the element of limited time. How would you go about retrieving a particular piece of information from this gargantuan library of unordered books and papers - with perhaps only a couple of hours of time available?
Certainly it would be futile to rumble around, picking up books and papers at random. You would want to consult catalogs and indexes, but, when you are dealing with millions upon millions of books, magazines and papers that are constantly being updated and added to, the information coming from any indexing system would bound to be frustratingly cumbersome and not always accurate or up-to-date. For the fine probing required to quickly and efficiently extract specific items of information, you would need intelligent, context sensitive help.
The only practical approach to finding information quickly in this environment would be to ask somebody else if they'd come across the information you wanted to find. In other words, you wouldn't start by looking at the books and papers: you'd start by asking people. Better than the library itself might be the library cafe, where you could ask around to see if anybody has come across any stuff dealing with the subject you are interested in. With a bit of luck, you might find somebody who has a special interest in the same subject as yourself and would know where the information you need is located.
There is no reason why you shouldn't use the library cafe to find all kinds of people. The combined interests and knowledge of all the people in the cafe could assist you to access a wide range of knowledge available from the library, both directly and indirectly. In this way you could treat the cafe as an intelligent interface to the randomly distributed, unindexed, information in the library.
Of course, if this were a real life situation, it wouldn't be long before other people discovered this way of getting information. The cafe would be filled to overflowing with people asking each other where various information could be found. From then on, the art of information gathering would assume the nature of a game: a game to attract and compete for other people's attention and cooperation. To compete successfully in this game you would have to be seen as a valuable person to know and to be friends with.
Almost immediately, this little trick of abstraction has transformed the crucial criterion from one of finding information to one of competing for attention and cooperation. Instead of being concerned about how to access information the emphasis switches to finding and attracting people.
We can now take this abstraction of the problem back to the original situation. Which means we now have to consider how we might create the equivalent of a library cafe to act as an interface between us and the Internet. This will involve constructing on our computer the equivalent of a social setting where we can interact with various people.
The Magical A-Life Avatars book then goes on to cover the kind of programming that would be needed to create a simulation of a library cafe - where people can have themselves represented by software agents that can exchange information on their behalf. This led to the concept of an "organic portal'.
To illustrate how organic portals grow and self-organize, let's use the analogy of the library cafe described in "Magical A-Life Avatars" (as described in the previous section). This is illustrated in figure 3.
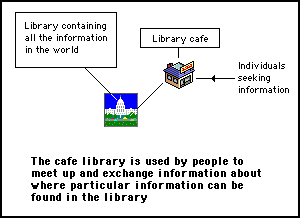
Figure 3 - The analogy of a hypothetical huge library, where people meet in the library cafe to help each other locate sources of information in the library
Imagine now, the library cafe getting so popular that it cannot hold all of the people who want to come in to exchange information. It would then make sense to expand the size of the cafe.
However, it might make greater sense if the owner of the cafe decided to build more cafes, rather than increase the size of the original cafe. In this way, different cafes could cater exclusively for some of the main groups using the cafe. For example, two of the main groups might be people interested in medical matters and people interested in Web design. This is illustrated in figure 4.
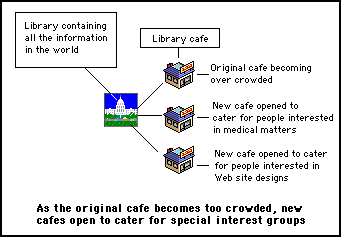
Figure 4 - The cafe is assumed to have a limited size. When it becomes too crowded, new cafes are created to cater for specific interest groups
If the new cafes also became too crowded, the cafe owner can expand the business by building more new cafes to cater for niche areas within the special interest groups. This is illustrated in figure 5, where the medical interest cafe has expanded into five new cafes: catering for people interested specifically in the subject areas of cancer, heart, mental health, dyslexia, skin.
Similarly, the Web design cafe is shown to have expanded to produce three new cafes catering for the sub categories of: programming,, graphic design and databases.
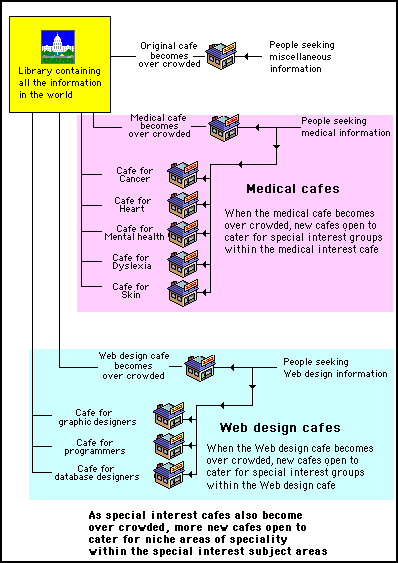
Figure 5 - Each cafe is of a limited size. When they become crowded, they breed new cafes that cater for sub sections of the main subject areas
This illustrates the principle of organic growth. The analogy helps describe how a system of cooperation can be created, which self-organizes into categories that arise spontaneously according to demand. Cafes and subject areas are not planned or predetermined: they grow according to the emerging interests of the users.
In an abstract sense, this is a network of intelligent nodes, where the intelligence is provided by people. Such systems are already occurring naturally on the Internet: in the form of list serves and news groups, where people gather together in special interest groups, where they share useful information and links to relevant Web sites. A stigmergic system is a more efficient form of this phenomena.
Critical to the understanding of such a system, it is important to appreciate that this is about exchanging pointers to information: NOT about exchanging the actual information itself. It is about the creation of designated meeting places - where people with similar interests can share and pool their knowledge about the location of relevant information they have discovered and evaluated.
Practical considerations
Building a system of library cafes, to help people exchange information may not be viable in the real world. However, an effectively similar system can be created in the world of the Internet, because the limitations and problems of the physical world can be overcome. This involves solving for a number of practical problems:
1) It isn't very efficient if people have to be present in order to exchange information.
This problem is solved by allowing people to be represented by personal software agents. These can exist independently on the Web to answer questions on their owner's behalf.
Stigmergic systems allow these agents to be created through the answering of a questionnaire; where the questions are those that might be asked by people seeking information in the relevant subject area
The answers give are then built into the "memory" of an agent, which will be able to convey these answers to people whenever the questions are asked.
This process is is shown diagramatically in figure 6.
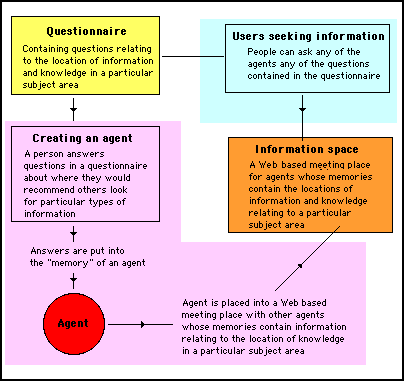
Figure 6 - People tell others about the locations of information they have found and evaluated by creating an agent. This agent has a memory which consists of answers they give to a questionnaire
Note: the questions, the agents are programmed to answer, are based upon FAQs (frequently asked questions) in a specialty subject areas.
The questions do not require information to be given - only pointers to where appropriate information can be found. In this way, people who have discovered and evaluated useful information sources within the scope of an FAQ question can let others know - through their agents - where this information is to be found.
Although it might be amusing to create simulated cafes to present these agents, in practice it is more efficient to make it appear as if the answers are coming from a regular database: in the form of conventional list structures. An example of such a simulated database output can be seen by clicking on the 'Example' link in the menubar.
Notice how the display can be rapidly changed to be able to compare agent answers on particular questions.
2) What questions to use when creating the FAQs to build agent memories
A conventional database solution to information retrieval would find this a difficult problem to solve. Every category has to have a unique set of questions to be asked and everyone would have a different idea as to what the questions should be.
With a stigmergic system of organic portals, this isn't a problem because the questions emerge out of user activity. Each subject category evolves its own unique set of questions - that can change and adapt according to user needs.
Note: such flexibility is possible because a stigmergic is designed to function like a biological eco-system. The infrastructure and content are continuously being reconfigured and rebuilt in response to user activity and feedback in each of the separate subject areas. This allows category hierarchies and sets of questions in each subject area to be continually changed and updated on an ongoing basis.
Note: If you click on the 'Example' link in the menubar you will be able to see an example of how a questionnaire is used in this way to create agent memories.
Notice the questions in the 'Assist information' section of these questionnaires. These are included to allow users to contribute towards the changing and updating of the questions included in the questionnaire. This allows the questions in each separate category to evolve its own unique set of questions, relevant specifically to the particular subject area.
3) The choosing and splitting up of the subject areas has to organized in some way
In the library cafe analogy, new cafes are created when a cafe gets over crowded. This is simulated in a stigmergic system by limiting the number of agents that can be present in any subject area. As soon as the set limit is exceeded, the largest group of agents with a similar interested is taken out to start a new subject area.
4) The hierarchical system must be highly flexible, able to respond and adapt to ever changing demands
This is the most revolutionary feature of a stigmergic system. It does not exist in the way a database or a computer application exists because it is not designed as a permanent, predetermined structure.
The system is made up of a large number of software components that combine, on demand, to build a complete system from scratch. These components act very much like the genes of a living organism, which can build a living organism after a procreation process.
Like living organisms, new generations of the complete system are constantly being generated, with each new generation using a slightly modified version of the genes. The successive generations including appropriate modifications to adapt to any changing demands or conditions in the information environment.
5) It must be scalable
A stigmergic system is easily scalable because it does not employ any real time, server side processing. Users interact directly with the information carrying agents; asking them questions without any need for a server side processor to be involved.
The system scales up simply by adding new meeting places.
6) There has to be some form of quality control over the content
There are four principal ways in which a stigmergic system can provide qualitative control over the answers given by agents.
Firstly, there is a facility for users of the system to comment, criticize or object to answers given by agents. The system can react speedily to these responses .
Secondly, it is easy to compare the answers given to any particular question by different agents. This will expose anomalies and offer a choice of answers.
Thirdly, the agents have to provide some indication of their authority and credibility.
Fourthly, the fact that subject areas are limited to the number of agents that can be present will enable new agents joining a subject area to replace poor quality agents or those with dated information. This enables the quality of the agent information to be automatically and continuously improved.
7) How do you get people to participate?
The reason these systems are called "stigmergic" systems is because they grow and evolve through a process known as stigmergy.
This is the name given to the phenomena of individuals reacting to an environment and in so doing, changing the environment in some way. These changes cause the individuals to respond to the environment differently.
Note: In biological systems (and human social situations), this positive feedback interaction (stigmergy), between individuals and their environment, can lead to the growth and evolution of complex systems.
It is the phenomena by which insect colonies can create complex architectural structures and communication systems. Business environments evolve in the same way.
This is why a stigmergic system has to be designed as a collection of gene like modules that are continuously rebuilding the system. It has to change form, quite substantially, from the time it starts with a hand full of users to a time when it might be dealing with millions.
Additionally, a stigmergic system is not dependent upon any central organization or control. It can be presented simultaneously, from any number of Web sites, each of which can have their own identities and areas of special interests. They can each concentrate on different interests, which will allow all kinds of subject areas to evolve in any number of different ways.