
Biological agents
Agent technology has much to learn from biological systems. Cells in particular are interesting to study because they communicate and cooperate with each other in the same way as objects in an object oriented programming environment. They may use a different kind of hardware for storing and processing information, but the techniques used are not so very different from those used by computer programmers.
By understanding how cells work, and studying the way they interact with each other in biological systems, many valuable insights can be gained to inspire initiatives in the design of complex, agent based systems.
Understanding cell hardware
The hardware key to biological life is a very stable class of chemicals called nucleic acid. It is the equivalent of silicon in a computer system. It can exist in the form of chains of molecules known as nucleotides. There are only four different nucleotides but each of them have a pair of complementary coupling points due to an element of oxygen on one side and a phosphate site on the other. The oxygen atom of any one of the four nucleotides can bind to the phosphate site of any other (see figure 10.5).
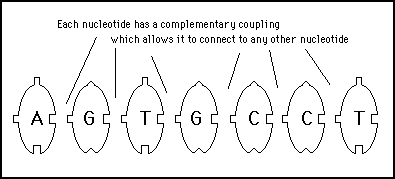
Figure 11s.1 - Nucleotides have an affinity to stick together due to a chemical formation at each side which provides a physical coupling supplemented by electromagnetic attraction
This ability of the nucleotides to bind side by side allows them to form long chains without it mattering which type of nucleotide is binding to which other type (see figure 11s.2).
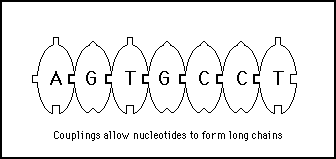
Figure 11s.2 - DNA can form digital strings of information because the four nucleotides can be linked to each other in any order
Already, from figure 11s.2, you can see how the joining up of the nucleotides can provide a number with a base of four. A long string of such bases can thus contain a massive amount of information. In humans, the string of nucleotides that form the DNA in every cell in our bodies is about six feet long and contains about three million nucleotides. This can be compared directly with the storage devices used for computers.
Note: In fact this DNA is not contained in a single length of DNA but in 46 separate lengths called chromosomes. However, this level of detail isn't relevant to our interest in the information transfer so we shall treat the DNA as being in a single string called the genome. In computer terms, the fact that DNA is stored on chromosomes is merely a hardware issue and is no more relevant to the information content than is the formatting structure being used on the hard disk of a computer system. Where possible, we shall be cutting out any biological detail which merely concerns hardware issues.
Three million nucleotides, with a possibility of four different nucleotides at each position provide the equivalent of a binary string of six million bits of information. In computer terms this is 750 megabytes. This gives us a direct way to compare the information carrying capacity of a biological cell with that of a computer system because 750 megabytes is of the same order of magnitude as the 650 megabytes contained on a CD-ROM.
A CD-ROM will hold its information in the form of pits in an aluminum foil. The length of the spiral recording this data on a CD-ROM is somewhere in the order of three miles. The length of the genome which holds this same amount of data is only about six feet in length, so, you can see how much more efficient is the hardware of a biological system.
Now you have to realize that there is nothing mysterious about storing binary data in a biological system. Nature just uses a very clever technique that should be considered as no more significant than the difference between using pits on a CD-ROM or using magnetic areas on a hard disk. It's just an alternative hardware solution for storing information in binary form.
The nucleotides also have another pair of complementary coupling sites which, from a hardware point of view, give DNA other very important characteristics. They allow each nucleotide to link up to a third nucleotide. These extra binding sites are not universal coupling points like the chain building coupling sites. These binding sites allow only specific pairs of nucleotides to bond - A will bind with T and T with A; C will bind with G and G with C. These specific coupling pairs are illustrated in figure 11s.3.
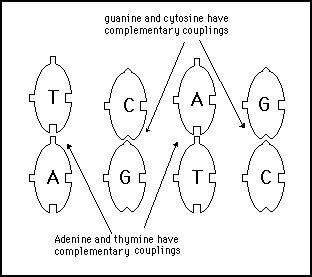
Figure 11s.3 - Nucleotides have additional binding sites which attract specific complementary nucleotides to bind to them
This extra bonding site allows the formation of a double strand, with one strand being the complement of the other (see figure 11s.4). This forms the famous "double helix" structure of DNA which carries our genetic code.
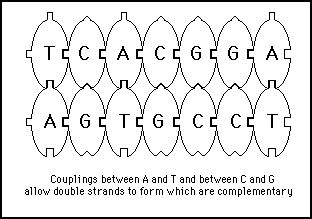
Figure 11s.4 - The complementary coupling sites allow strings of DNA to form into double strands with one strand being the complement of the other. The two strands form into a double helix
The first advantage of the double strand structure is the increased stability it provides. Although nucleotide bonding is quite secure there is so much jostling in the environment of a cell that individual nucleotides can get displaced. The fact that a gap will automatically attract a replacement nucleotide of the correct type greatly adds to the long term stability of the structure (see figure 11s.5). This is of course a hardware issue and has no affect on the information or its processing.
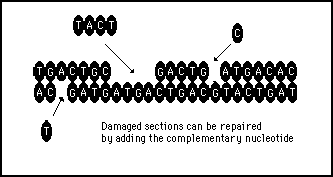
Figure 11s.5 - A double stranded structure of complementary strands allows damaged sections of the strand to be repaired by referring to the complement nucleotides
More applicable to our interest in information processing and transfer is another advantage of a double strand which is that the DNA be split into two complementary halves (figure 11s.6).
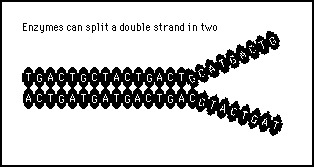
Figure 11s.6 - A chain of nucleotides can be split down the middle
The ability to split a length of double stranded DNA down the middle allows two complementary copies of the same chain to be made (see figure 11s.7).
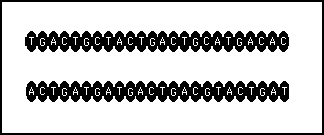
Figure 11s.7 - The splitting process forms two separate chains with one the complement of the other
The two halves of a DNA section that has been split down the middle can each rapidly build an additional complementary strand. This results in the splitting operation producing two copies of the original (see figure 11s.8). This process has a direct analogy with the copying functions available on all computer systems.

Figure 11s.8 - The splitting of strands and then regrowing the complementary strands results in the original strand being copied and is exactly analogous to the way in which binary data is copied within a computer program
The principle of complementary bonding is also used by biological systems to retrieve information from a DNA storage source. Figure 11s.9 shows (diagrammatically) how nucleotides can be matched to a strand of DNA to in effect "read" the message they contain (see next chapter for a description of this reading mechanism). The nucleotide strand which is formed as a copy the information from a DNA strand is called messenger RNA (mRNA ). Again this is a hardware device which illustrates yet another clever mechanism which nature has evolved to manipulate and exchange information.
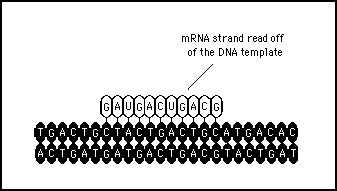
Figure 11s.9 - Complementary strands of messenger RNA can be created to match sequences of nucleotides. This provides a way of reading off the information contained in the genome
Being able to create copies of DNA sequences allows the information contained in the DNA to be transferred to other places in the cell for processing. Figure 11s.10 illustrates how the information copied from the DNA in the nucleus is passed on via the mRNA to a processing unit (a ribosome) within the cell where the digital information will be transformed into analog form.
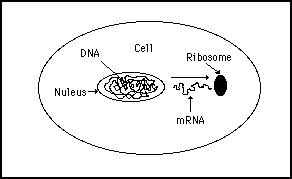
Figure 11s.10 - Information held in the nucleus on the genome can be transferred to ribosome processing units in the cell where the binary data is converted to analog form
The main function of the DNA in the nucleus of a biological cell is to hold "genes". Although genes are attributed almost metaphysical qualities by the popular press these "genes" are simply the information necessary to construct particular proteins. Every gene describes the manufacturing instructions for a different protein and there are of the order of 100,000 different proteins described by the genes on the genome in a human cell.
In terms of an analogy with an A-Life avatar cell, each "gene" in an A-Life avatar cell engine would be equivalent to a programming expression or instruction. In this way many different A-Life avatar cell "genes" can be mixed together to create objects and handlers as well as providing messages and control variables.
The genetic instructions in a biological cell, are coded as a language using the four nucleotide bases (A, T, G and C) as an alphabet. This four letter alphabet is used to make sentences of three letter words. The three letter words are called codons and the total vocabulary of this language is limited to 64 words or codons (note: three positions with a possibility of four at each position = 64 possible combinations). The sentences in this language can be of any length and each sentence will describe the complete manufacture of a protein.
Proteins have many different names such as peptides, enzymes, hormones, transmitters, etc. They can vary enormously in size and come in innumerable forms and shapes but they can all be described by this simple alphabet because they are each constructed out of a maximum number of twenty different kinds of amino acids.
The 64 word language of the genetic code is quite sufficient to describe the manufacture of any protein because only twenty of the 64 words are necessary to specify those twenty amino acids. The sequence of nucleotides are read off of the messenger DNA three at a time (by a cell molecule called a ribosome) and at each reading the specified amino acid is added to a chain (see figure 11s.11).
Note: The mechanism for creating the amino acid chain from the messenger RNA is similar to the way in which the nucleotides are joined together. Each codon specifies a complementary codon (tRNA)which provides a specific docking site which attracts the appropriate amino acid. The amino acids are then popped into place as if they were beads in a popper bead necklace.
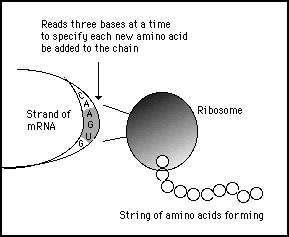
Figure 11s.11 - The digital information on the genome is read as words to provide the instructions to make a particular protein. It is a digital to analog conversion, whereby each protein is analogous to an instruction or message used in A-Life avatar cells.
One of the 64 words of the genetic language codes for a start instruction and three others code for a STOP instruction. When the ribosome encounters a STOP word, the string of amino acids is set free, whereupon it coils up into a characteristic shape for the protein which has been constructed (see figure 11s.12).
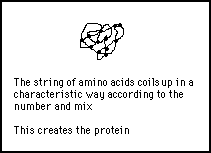
Figure 11s.12 - All amino acid sequences coil up into a characteristic shape that creates a protein which is an analog form of the original digital information from the genome
The coiling up of the protein is not a haphazard random process. The amino acid sequence configures itself according to the strict laws of thermodynamics into a state of minimum energy. This gives every protein a specific characteristic shape - an analog form of the information. It is this feature which allows the cell to function as a computer.