
Information processing in a biological cell
When dealing with a novel situation it is always useful to be able to turn to analogies, metaphors or other forms of the situation which have occurred before. In this way educated guesses can be made as to how to proceed intelligently towards eventual mastery over a new situation.
The previous chapter described how computers and biological systems have many similarities. It showed that if you looked beyond the hardware to abstract out the essence of the processes involved there is a lot of common ground. In particular, the flow and processing of binary data was seen to be similar in biological and computer systems even though different types of transmission vectors were involved.
For these analogies to have any useful influence over the way we design communication systems for the Internet we need to take a closer look at the way in which data processing and messaging techniques have evolved in biological systems. We need to be able to relate the chemical activity directly to the programming techniques used on the computer.
As we saw from the previous chapter, digital information on the genome is converted into protein analogs. The key to understanding how this can result in data processing and computer like activity is to take a look at the physical interactions.
If and when it is activated, each gene on the genome results in a particular sequence of amino acids being formed which curl up into a particular characteristic shape. One gene can specify a protein which coils up in such a way that it forms a complementary shape to the protein specified by another gene. These complementary shapes can have an affinity towards each other: one fitting into the other like a key into a lock. In this way, one protein can represent a message and the other can act as a receptor which attracts and traps that message. Figure 11s.16 shows this in diagrammatic form where the complementary shapes of a receptor molecule and a message molecule cause the two protein molecules to bind together.
In terms of computer programming this is analogous to the way in which a message is directed to a particular object. The message is sent with an address: i.e. the shape on its surface. When a message in a computer program reaches an object it will trigger a handler. When a protein message reaches its target the resultant activity is dependent upon what other proteins the receptor is connected to.
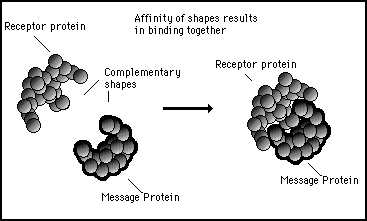
Figure 11s.16 - Genes on the genome specify proteins with specific shapes. If these shapes are complementary the protein molecules will have an affinity towards each other and they will lock together
The critical point to realize is that proteins assume their shape according to strict physical laws associated with electromagnetic charges. If the two proteins illustrated in figure 11s.16 affected each other such that their complementary fingers squeeze into each other, the bond could be very strong and it would be hard to separate the two proteins by the normal thermal vibrations which occur in a cell.
However, as strong as the bond between two protein might be, it is possible to change the bonding strength by using another protein to change the shape of one or other of the proteins. Figure 11s.17 shows a release protein whose surface is attracted to the complementary shape of the back of receptor protein. When the release protein and the receptor protein bind together this can cause a radical change in shape of the receptor protein such that it no longer attracts or forms a bond with the message protein. This is illustrated in figure 11s.17.
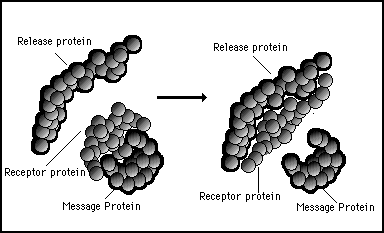
Figure 11s.17 - The joining together of proteins can cause their shapes to change. This can turn strong affinities into weak affinities
From a computer programming aspect this is a very useful mechanism to be able to call upon. It is a logic gate which can be used in a number of different control situations:
if releaseProteinNotPresent then
connectMessageToReceptor
else
letMessageActivateReceptor
end if
Clearly, this ability to be able to control a bonding characteristic can be used in many different ways. This is more easily understood if you realize that biological systems do not work with a single message being sent to a single target. The message protein shown in figure 11s.17 might be generated in thousands and the receptor proteins might also be present in thousands. The result would be measurable in terms of an aggregate value for thousands of such bondings.
This is quite unlike computer programming techniques where single messages go to specific targets. To understand how multiple messages work in biological systems you have to consider the effect the bonding might have on the density of the molecules within a cell. If the release protein is not present in large numbers it will mean that most message proteins are bound to receptors and its presence in the cell cytoplasm would be low. If on the other hand there are very many release proteins floating around they would constantly be releasing trapped messages: ensuring a high density of messages in the environment. In this way the message could act as a variable in the cell with its value determined by the relative activates of the genes producing the release and receptor proteins involved. This variable can then be used to control or modify other chemical reactions in the same way that a variable in a handler might control or modify instructions.
A variety of different protein combinations can be used with this very simple mechanism of complementary protein shapes to construct complicated programming structure using several different variables. They can quite easily include mechanisms like repeat loops and if... then... else... structures.
Boolean logic is at the heart of all computer processing. This is also easily arranged with protein mechanisms; AND, OR and NOR gates can be arranged very simple by using this principle of modifying protein shapes. As an example let us look at a protein AND gate. Figure 11s.18 represents four different protein shapes that can be called from the genes of the DNA. One of the proteins acts as a receptor, another as an effector while the other two are messages which both have complementary affinity shapes with the receptor.
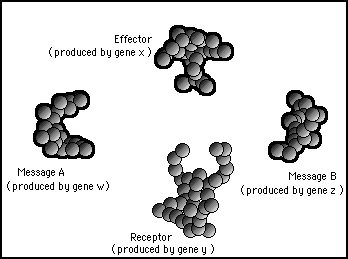
Figure 11s.18 - Four possible proteins each with characteristic shapes. Each protein is specified by a separate gene.
The receptor and the effector proteins are shaped such as they have a strong affinity for each other at a particular binding site. They will normally be found in the cell bound together as a single molecule. This is illustrated in figure 11s.19.
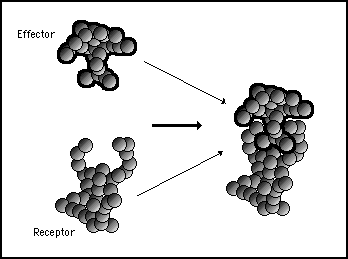
Figure 11s.19 - The effector protein and the receptor protein have a strong affinity and complementary shapes. This causes them to lock together in the normal environment of the cell
If message protein A is around, it will bind to the receptor protein due to complementary surface shapes, but, this binding may not affect the bonding between receptor and effector at all (see figure 11s.20).
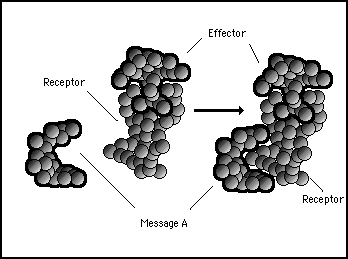
Figure 11s.20 - Message A protein has an affinity for the receptor protein and readily binds to it but the combination does not rearrange the electromagnetic forces sufficient to affect the binding between the receptor and the effector
Similarly, if we look at the effect of message B it also may have no effect on the bonding between receptor and effector. This is illustrated in figure 11s.21.
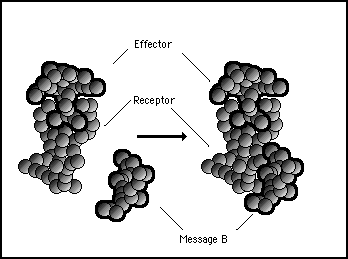
Figure 11s.21 - Message B also has an affinity with the receptor protein but its binding has no effect on the binding between the receptor and the effector
If protein message A and protein message B are both bonded to the receptor the least energy configuration of the complex may be such as to change the shape of the surface bonding with the effector protein. In this event the effector protein could be released as a result of message A AND message B both being present in the cytoplasm of the cell. This mechanism can therefore function as a logical AND gate as illustrated in figure 11s.22.
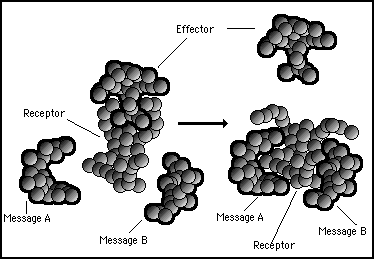
Figure 11s.22 - The effect of both message A protein and message B protein binding to the receptor causes a change in the electromagnetic patterns. This changes the shape of the receptor/effector binding site and releases the effector. This constitutes a chemical AND gate.
Similar to the way in which an AND gate is constructed out of protein molecules, other types of logic gates can be created. Effectors can be released if any of several proteins are present or NOT present. Effectors can be released if specific combinations are present or are not present. This allows all kinds of complex processing operations to be performed. Molecular switches can be switched on or off by all manner of interacting controlling factors, allowing logical manipulation of data or information every bit as ingeniously as a digital computer.
Seeing how easy it is for variously shaped protein complexes to receive and send messages - and seeing how easy it is for these messages to be regulated and controlled - it then becomes understandable. The chemical activity in the environment of a cell is directly analogous to the activity which occurs in the object oriented environment of an A-Life avatar cell.
In the above example, an effector protein was released as a result of certain genes being turned on (i.e., those giving rise to the controlling message proteins). As these genes are turned on by other protein messages you could think of these other protein messages as turning on the effector protein directly. In other words you need not consider all the intermediate steps in the process - just the first and last.
This is what we do when we program object oriented designs with high level programming languages in A-Life avatar cells. We don't have to think about all the detail of getting binary strings from RAM and operating on them with the registers in the central processing unit. We can simple think in terms of:
If A is true and B is true then send a message to object C else send the message to object D
It is important to be able to abstract away from the hardware detail in this way. By considering only the essential effects of software processes, we can more easily compare biological systems to computer systems. Figures 11s.23 and 11s.24 illustrate this concept of abstraction, by reducing two complex hardware processing procedures to the same simple software instruction.
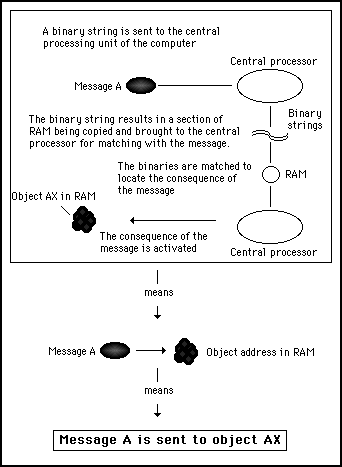
Figure 11s.23 - In a computer, the complex processing of binary data can be abstracted out to simple programming instructions such as indicating that message A is to be sent to object AX
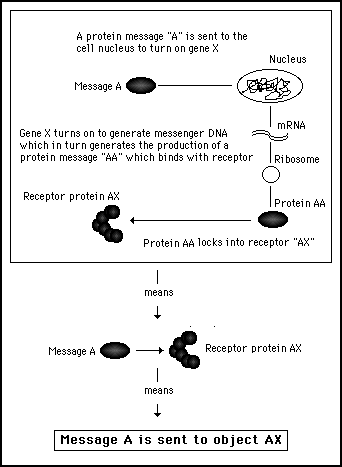
Figure 11s.24 - In a biological cell, the arcane chemical interactions involved in cell activity can be abstracted out to describe the process in terms of only the start and finish. This produces a language and syntax which is the equivalent of a high level programming computer language
The release of an effector in the environment of a biological cell is analogous to a message being sent from one object to another in an object oriented programming environment. In a computer, we know that a message from one object to another reaches the right address because of the way in which the central processing unit of the computer can search RAM to find a matching binary sequence. At this memory address it will start to look for a match for the message and thereby activate the sequence of instructions called for by this message.
Although the hardware in a biological cell is radically different, the biological cell carries out an almost identical procedure. An effector protein might be in the form of an enzyme that is packaged up and dispatched to the nucleus (when used for this purpose the protein is known as a transcription factor). This enzyme would have a characteristic shape that will fit snugly at only one position on the helical structure of the genome. The correct position is confirmed by fingers on the enzyme reaching down to the nucleotides at that position and identifying the exact nucleotide sequences (see figure 11s.25).
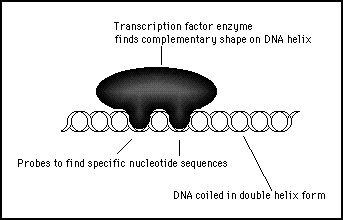
Figure 11s.25 - A transcription protein is sent to the nucleus which binds to a particular location on the genome. This is analogous to the central processing unit on a computer finding a matching sequence of binary data in memory
When the transcription protein finds the correct location on the genome, it opens up the helix and attracts another protein enzyme called mDNA polymerase which is present in large numbers in the nucleus. This mDNA polymerase will attach itself to the opened helix and starts sliding along until it comes to a nucleotide sequence that indicates a START RECORDING. At this position the mDNA polymerase protein will start reading off the nucleotide sequence and begin creating a copy in RNA to produce an mRNA messenger molecule. This continues until the mRNA polymerase molecule reaches a nucleotide sequence which codes for STOP. At this point the mRNA is released and sent on its way to an appropriate ribosome to create a new protein specified by that particular gene sequence of nucleotides (see figure 11s.26).
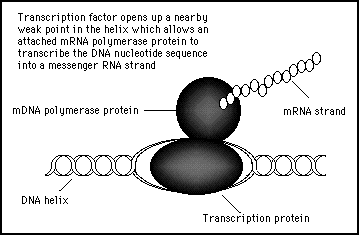
Figure 11s.26 - The transcription factor protein opens up the helix at a specific location and then calls upon another protein to read off the gene which starts from that place
Clearly, although the hardware is completely different from that of a computer, the message passing procedures of a biological cell is somewhat similar to the message passing procedures within an A-Life avatar cell. Human digital computers organize message activity via a central processor unit. Biological systems organize message activity via the nucleus and a system of protein objects. Completely different hardware but the essence of the underlying software procedures is the same.
Manipulations of molecules in a cell, which most resemble the functions of a central processor unit in a computer, are carried out by a class of proteins known as enzymes. Enzymes can join proteins together or cleave them apart. They act as catalysts in the sense that the chemical activity they promote will happen only in their presence (or at least it will happen only at speed in their presence) and leave the catalyst proteins themselves unchanged as a result the chemical process they catalyze.
As with the protein interactions discussed above, enzymes rely on an affinity (force of attraction) between themselves and the substrate molecules they catalyze. In this way, all enzyme interaction is governed by physical laws of mass attraction.
A common processing operation of a central processing unit in a computer is to join two specific strings together. The enzyme activity that emulates this process is illustrated in figures 11s.27 to 11s.29. The first of these shows samples of two types of molecule which may be present in a cell. Without any catalyzing enzyme present, these molecules exhibit no particular affinity to each other and the environment of the cell might be highly populated with these two types of molecule.
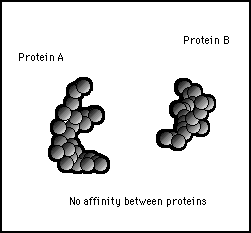
Figure 11s.27 - Two protein molecules (A and B) that may be present in a cell in large numbers but have no particular affinity to each other so they will not bond together
The protein population of the cell can be quickly changed by introducing an enzyme that has an affinity site on its surface for both types of molecules. This will cause the enzyme to attract the other two molecules to points where they can lock onto its surface.
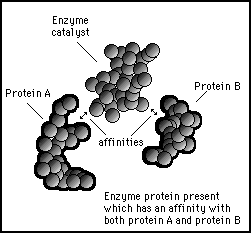
Figure 11s.28 - A catalyst enzyme will have sites of affinity on its surface for the substrate molecules it is going to catalyze
The characteristic of a catalyst molecule is that its presence will alter the dynamic shape configurations when it binds to its substrate molecules. In this example the two proteins A and B which previously had no affinity will now exhibit a strong affinity towards each other.
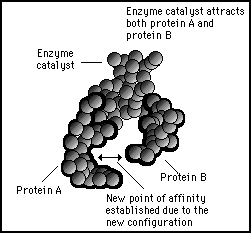
Figure 11s.29 - Catalyst enzymes reconfigure electromagnetic patterns and physical shapes of the substrate molecules such that they will have an affinity to each other
When the substrate molecules bind together, the electromagnetic shapes distort their shapes such as to release the enzyme that catalyzed the reaction. This leaves the substrate molecules locked together to form a new stable molecule.
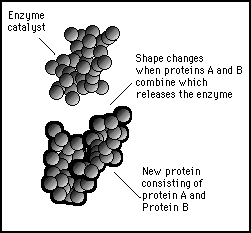
Figure 11s.30 - When the substrate molecules bind together they release the enzyme catalyst allowing it to go free to attract another substrate pair and repeat the process again.
Using different enzymes and different combinations of substrate molecules the composition of cells can be changed very rapidly to in an analogous way to the way in which computer central processor units change the values or contents of variables, alters messages, creates AND or NOR logic gates. If the language and syntax of the protein shapes were known it would be easy for molecular biologists to program this enzyme activity to perform sophisticated series of programming operations. This is one of the ultimate goals of science.
Conversely, protein enzymes can split proteins up into smaller sections by cutting them at specific points. This allows many protein messages to be strung together in the cytoplasm of a cell. It is analogous to a list structure in the syntax of most computer languages where a number of variable can be strung together and referenced when needed in the program. Figures 11s.31 to 11s.33 illustrate diagrammatically the principle of cleaving through a protein.
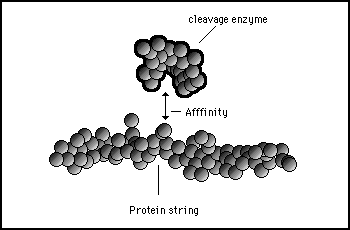
Figure 11s.31 - A cleavage protein is specific for a particular point on a target protein. It is attracted to the right cutting position by the complementary affinities of surface shapes
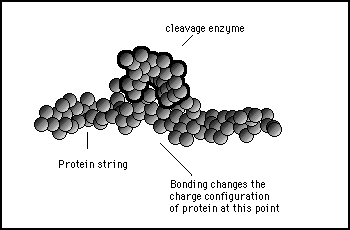
Figure 11s.32 - When the cleavage enzyme binds to the protein it will cause the internal charge configurations to change
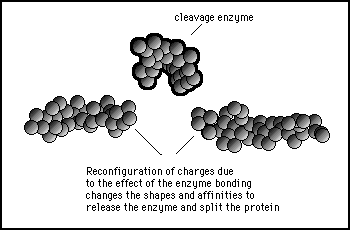
Figure 11s.33 - The reconfiguration of the internal structure of the protein causes it to split at the binding site and change shape so that the cleavage enzyme no longer bids to either of the separate protein sections produced
As complicated as this protein cleaving process appears to be it can be abstracted out as being equivalent to the LINGO programming instruction:
getAt(theProteinList,num)
To somebody unfamiliar with Lingo, this computer instruction would appear to be just as arcane and unfathomable as the chemical processing details might appear to a non-biologist.