
Organic portals
by Peter Small
One of the first commercial projects where we employed stigmergy was the "Cancer Treatment World Project". This involved trying to cope with an impossibly large number of different varieties of cancer. To overcome this problem, we used the concept of organic portals: self-organizing navigation systems that evolve their own hierarchical categorization as a result of user activity.
This article was written at that time, to try to explain how a system can create its own categories as it grows.
1) Problems in explanation
There seems to be several reasons why the concept of organic portals is so hard to understand:
Firstly, it is easily confused with conventional database solutions.
Secondly, it is a strategy, not a solution or an application.
Thirdly it calls upon many sophisticated and elusive concepts.
Fourthly, it can be wrongly identified with conventional user participation sites.
Fifthly, much of the practical application is counter intuitive.
There couldn't be a more formidable series of conceptual hurdles to jump, so, perhaps the best way to start is by explaining the need for organic portals and the advantages they bring.
2) Need and advantages of organic portals
Stigmergic systems in the form of organic portals are strategies that can be developed for a wide variety of purposes. They are particularly useful for facilitating cooperative and collaborative activities because they bring people together efficiently. This makes them suitable to use for leveraging skills and knowledge in large companies. They can be used to organize outsourcing.
Organic portals can also provide an organizing framework to deal with large amounts of ambiguous, conflicting or volatile information.
To appreciate when and where an organic portal can provide a solution that is superior to solutions using conventional database technology, it is necessary to understand the limitations of existing methods of obtaining information
Limitations of existing information retrieval techniques
A definitive source of information on methods currently being used for information indexing and retrieval is The Spire Project (set up by an Internet research resource and think tank).
It is worth spending some time looking around this site because there are some excellent descriptions of most of the major search engines in use today - together with explanations of their strategies to index and retrieve useful information.
Their limitations are discussed in two articles by the manager of this project, David Novak:
Keeping up to date with Internet Research Technique and Theory
The Growth of the Internet Should Still Scare You
In these articles, David Novak writes:
"I am concerned about our attitude to the growing quantity of information on the Internet.
"...organizing the internet is not a problem that will be solved. It only looks that way to people unaware that babies put on a lot of weight fast. The truth is that despite much effort, much of the internet will forever be un-catalogued and not indexed. The volume, trends and logic has made this a predestined impossibility. We will only ever arrange a fractional (and diminishing) percentage of the internet".
It is in these areas of limitations, where organic portals can be applied: to get results which would not otherwise be achievable.
Overcoming redundancy, ambiguity and change
Databases and search engines cannot deal very well with redundancy, ambiguity and change. This is because these technologies are based upon algorithms, which have very limited capacity to utilize anything approaching the intelligence of a human brain.
An organic portal overcomes this problem by creating a framework that introduces a human element into the process of sorting and selecting.
Normally, the use of humans in any system of information processing involves excessive cost because human labor is an expensive commodity. This is where organic portals have an advantage because they can eliminate or minimize this cost by making use of stigmergy: the natural tendency for humans to compete, cooperate and self-organize (See the link 'Explaining stigmergy'.
3) Explaining a formatted space
Organic portals are based upon making use of an abstract formatted space. The problem is that these abstractions are difficult to describe. It is a mind thing, not something that can be easily demonstrated.
To try to explain this elusive concept in my books, I used the following story:
Presenting a new concept:
Time: Early 1970's
Place: The president's office in a large electronics company in California
"The president will see you now."
The young man was ushered into the president's sumptuous office and shown to a seat in front of the huge desk dominating the room. He waited nervously for the president to finish reading through the pile of papers on his desk. The president looked up at him.
"You the guy with the killer app for these new-fangled computer things?"
"I think so", replied the young man nervously.
"What is it, then?"
"Well, it's sort of difficult to describe", began the young man hesitantly. "It consists of a grid of rectangles covering a computer screen".
"What's in the rectangles?"
"Nothing".
"Nothing?"
"Well, not until the user puts something into them."
"What sort of things?"
"Text and figures, but figures mostly, because the rectangles are used to do mathematical operations on the figures".
"So each rectangle is programmed to act like a calculator?"
"Well, they could be. It depends how the user programs them."
"You mean these empty rectangles have to be programmed by the user?"
"Yes, that's right. The rectangles are connected to each other by some kind of formula."
"What’s the formula you use to connect up these rectangles?"
"I don't provide the formula."
"Who does?"
"The user."
"How are these rectangles connected to each other, then?"
"They aren't connected until the user supplies the connections."
"So, this killer app of yours consists of a grid of empty, unrelated rectangles that the user has to fill up with figures and connect together with their own programming and formulae."
"That's right."
"What are you going to call this killer app of yours?"
"I thought of calling it a spreadsheet."
"Nice name. Thank you for coming along."
"Thank you for seeing me."
"Good-bye."
"Good-bye."
The above scene seems humorous to us now because we know what a spreadsheet is and we can see how easy it would have been for somebody without previous knowledge to miss the point of having empty rectangles in a spreadsheet. The idea that you can model a business or a manufacturing process on a spreadsheet consisting of nothing but empty cells isn't instantly obvious. However, as the Taoists say, "The usefulness of a bowl comes exactly from its emptiness."
This story illustrates the problem of trying to explain the idea of an abstract formatted space. It is not an intuitive concept to understand. In the same way as the president in this story missed the point of using a formatted space in a spreadsheet, most people miss the point of using a similar abstraction for organic portals.
However, most people are familiar with the idea of organizing information into categories. Libraries, for example, organize information within a hierarchical system of categories, whereby the reading matter is repeatedly subdivided into increasingly narrower subject areas.
Such a system allows the physical space in a library to be formatted into sections, book cabinets and shelving: enabling people to know where to look to find the type of book or information they need.
A database will format computer storage space in much the same way as libraries format their racks of books: categorizing information so that it can easily be located.
Once the information is formatted, libraries, and even more so databases, can index the formatted information in many different ways to locate specific items of interest. For example, items of specific interest can be located by using a system of key words that give a brief description of the information required.
This system of formatting a space and using various methods of indexing to be able to locate a particular item of information works well only if it is possible to accurately index all the information. But, in the environment of the Internet this is not possible. This situation is described in the book "The Ultimate Game of Strategy":
"...in particular, I was interested in the way in which the human brain was coping with the problem of information overload and its ability to extract useful information from the gargantuan mountain of knowledge represented by the Internet and the Web.
I'd likened this ever expanding mountain of knowledge to a vast library, where all the books are randomly placed on shelves and the librarians can't keep up with sorting and classifying all the new books coming in each day. In such a scenario, it would be a hopeless task to go into this library to try to find a specific piece of information."
From this metaphorical view point, it is easy to see how there would be many logistical problems involved in sorting, categorizing and locating information in a volatile environment.
This excerpt continues:
"A more sensible strategy would be to go into the library cafe, to see if there is anyone in there who'd come across the information that is needed. It is much easier to ask a person than to try to wade through piles of papers and books.
The Internet represents such a cafe. It contains millions of people who have been routing around in various parts of the Web looking for information. If there is any particular knowledge that needs to be known, there is a fair chance one of them will have already come across it. The trick is to find out which one."
This is the essence of an organic portal. It isn't about formatting a space to store information. It isn't about indexing information. It is about formatting a space to allow people to find somebody who can tell them where to find the information they need.
In other words - using the library metaphor - the formatting is needed in the library cafe, to help people find others who can help them. It is not used in the library to organize the information.
This is a difficult concept to get across, because most people are more familiar with the idea of using a computer to store information. They are not familiar with the use of a computer to keep up a running record of a dynamically changing network of routes and meeting points.
A useful metaphor to use here is the network of pheromone trails that ants lay to guide each other to sources of food. These trails can be thought of as a dynamically changing network of routes and meeting points - where the database hardware for recording the current position is the landscape. An organic portal acts like such a landscape, providing a suitable repository for trails that lead to sources of information.
This is the biggest stumbling block in the understanding of organic portals. They are concerned only with the trails and pointers to information: not the information itself. In other words, organic portals do not store any information, they simply provide a means for people to find others who know where information can be found.
Note: you might take comfort from the fact that this is all self evident when the system is operational. It is only the abstraction of the theory that is difficult to explain.
6) Creating an environment for self-organization
Although it is essential to show a demo of what an organic portal looks like (the CTW project for example), a demo doesn't help with understanding how the system works because it looks so much like a conventional database solution.
It may look like a database solution. It may act like a database solution. But, it is something far more ingenious and subtle: the demo is illustrating an elegantly efficient method of information processing that has been copied from the insect world
After all, insects don't use databases do they? So, what do they use instead? How do they achieve their highly complex systems of organization? This is what stigmergic systems are about — opening up new possibilities that transcend some of the limitations of conventional database solutions.
Conventional databases embody a structured organization for the information they contain. This enables programs to be written(algorithms) that can sort, classify, merge, and select in numerous different ways. However, this processing and ordering is invariably internal and mostly predetermined. There is little scope for the processing to evolve and adapt to change, outside of the control of the central organization.
Stigmergic systems, on the other hand, have no central organization or control. They can evolve from many independent sources (this is the way biological systems grow and acquire organized complexity).
This concept, of an organic system without any centralized control, is not intuitive or easily understood - particularly from a background of database technology. It might help therefore, to take time out to consider the difference between structured and virtual hierarchies.
Structured and virtual hierarchies
Unlike databases, the hierarchical structure of a stigmergic system has no predetermined structure. Instead, it 'grows' its own virtual organization in the form of a virtual hierarchy.
The difference between a structured hierarchy and a virtual hierarchy is illustrated in figure 1:
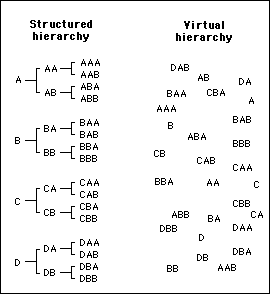
Figure 1 - These are identical hierarchies. One is structured, the other is virtual
Although the virtual hierarchy in figure 1 appears to be disorganized, there is an implicit order by virtue of the addresses given to the various elements. This can be demonstrated by showing how it is possible to take a route through either hierarchy simply by going through an ordered sequence of names. This is shown in figure 2, where a route "B -> BA -> BAB" is taken in both a structured and a virtual hierarchy.
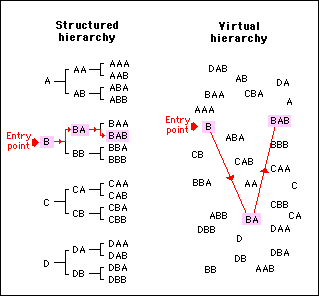
Figure 2 - The physical arrangement of a hierarchy is not important as long as each element in the hierarchy is given a name corresponding to its position in the hierarchy
The physical arrangement of a hierarchy is not important as long as each element in the hierarchy is given a name corresponding to its position in the hierarchy
Understanding how elements in a hierarchy can be ordered simply through a suitable naming convention is the important paradigm shift to be able to escape from the confines of conventional database technology.
Figure 3 shows how a hierarchical structure can be maintained through a naming convention, even when the elements of the hierarchy are located randomly in totally different domains.
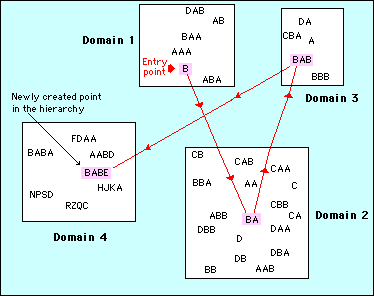
Figure 3 - A hierarchical order can be maintained through a naming convention, even when the elements are randomly distributed over a number of separate domains
This is the way the World Wide Web is organized. It consists of billions of 'freely floating' documents which, because of their URL addresses and a system of links, can give the appearance of being ordered into Web sites.
These Web sites can be further ordered and structured by many different kinds of directories that can each independently reconfigure the organization in a multitude of different ways.
It is this same flexibility that underlies the organization of cells in living organisms and the meeting places in the organic portals of stigmergic systems.
The main significance of this virtual structuring is that the elements of a system do not have to be centralized. The system can manifest as a result of many independent contributions - processing and organizing the information - from many independent sources
•••••
A useful analogy
Think of the elements in this system as being like a sea full of ice floes. If each ice floe has a code number, these numbers can be arranged to relate to each other in a hierarchical way.
The ice floes could then be represented on a computer screen as a hierarchical structure and it wouldn't be apparent from the presentation that the ice floes were actually independent, freely floating entities.
In this way, an illusion of a hierarchical structure can be created This explains why the seemingly rigid hierarchical structure of a stigmergic system is actually an illusion.
•••••
Such a conceptual model is totally at odds with the concept of a database, where the very essence is about keeping control confined to a tight, central organization. Database solutions are designed to impose order and work best in steady state conditions.
Stigmergic systems, on the other hand, deal with chaotic conditions, where the imposition of order is not practical. Order is brought about by enabling the system to organize itself.
Certainly, a conventional database can easily handle the mechanics of the system as it is shown in the Cancer Treatment World demo, but, when a real life version is in operation and it is scaled up to handle thousands of different meeting places it becomes progressively more difficult to control except by standardization — resulting in a system rigidity that is sluggish to adapt and evolve.
The weakness of such database systems is that the larger the system grows the faster the system degrades. This is because such systems grow exponentially and it becomes increasingly more difficult and expensive to maintain control over the quality of the information it contains.
By creating a system that is decentralized and designed to self-organise and evolve in a multitude of different ways, each meeting place can develop a uniqueness of its own and incorporate its own procedure for quality control.
In this way, an organic portal evolves much like the World Wide Web, with each meeting room, like Web sites, manifesting and evolving as an independent entity.
The difference though - between Web sites on the Internet and meeting places in an organic portal - is that Web sites manifest in isolation, whereas the meeting places in stigmatic system manifest within a self-organizing, formatted navigational framework.
7) Explaining a self-organizing, navigational framework
The Cancer Treatment World project seems to suggest a hierarchical structure to the subject areas in the information space. To most people, it is inconceivable that such order could come about without deliberate design.
In the world of computers, order is normally imposed. Structure is predetermined so that information can be organized and monitored by algorithms. Anything that cannot be indexed and controlled is usually assumed to be unpredictable and chaotic.
It is no surprise then that most people find the idea of a self-organizing, navigational framework a difficult concept to come to terms with.
The best way to explain how self-organizing frameworks come into into existance is to use the analogy of ants laying pheromone trails as they search for food. This happens because ants have genes that allow them to write and read these trails.
The trails that lead to substantial resources are reinforced through frequent use. Other trails evaporate and quickly fade away. This leaves a landscape filled mostly with trails that are rewarding to follow.
By suitably using Web log statistics, such a system can be emulated for creating and maintaining pathways to meeting rooms in an organic portal. In this way, a self-organizing network of navigational pathways can be created and maintained automatically: without the need for human control or supervision.
Most people will understand this analogy quite easily, but, where they will get lost is when you try to explain how this system isn't run through a database, but, through code modules activated in a user's browser.
This is where an analogy with genes comes in useful. These modules of code can be likened to the genes of ants, where they empower the ant to read and write pheromone trails.
Nature takes advantage of this modular system of genes to provide organisms with complex behavior patterns - enabling them to adapt and evolve. Organic portals employ this same technique: using modules of code to help users find and exchange information in a variety of different ways.
Not only can these modules of code allow a user to read and write pathways, they can also provide the user with ways to leave messages and exchange information in the meeting rooms.
The main advantage of this system is that organic portals can be run at a low cost and are easily scalable without any loss of speed or efficiency. By using a system of client side components, there is not the exponential rise in complexity that you get with conventional database systems as the system expands.
This makes organic portals suitable for use in many situations where conventional database systems usually break down. This would be where information content is volatile and subject to constant change and where the total volume is unknown or unpredictable.