
Chapter 9
A formatted people space
The first clue
I must admit that part of the solution was currently in my mind because, at the time I received Tillman Pearce's e-mail, I was making preparations for a talk I was to give at BOT 2001 ( a seminar being organised by Internet.com and taking place at the Fairmont Hotel in San Francisco in January 2001). The talk was to be entitled: "Using bots to create a living database".
The principle behind a living data base is that it consists of a system of people rather than information. This, as you might recognise, is similar to the rag sorting business described above and is also a constantly reoccurring theme running through the books in this trilogy. The principle tenet is that people are needed where uncertainty, change and volatility render logical and algorithmic search techniques useless. Only the human brain can provide the kind of intelligence needed.
To appreciate the advantage of a living database, let's first examine a conventional database – an outline view of which is shown diagrammatically in Figure 9.1.
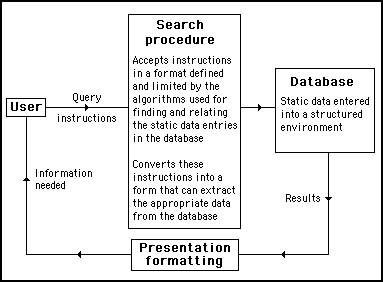
Figure 9.1
Outline of a conventional database
Information in a conventional database can be cleverly formatted and indexed to facilitate retrieval. Data can be sorted, mixed, matched, compared and selected using all manner of criteria and conditionals, but, the algorithms used have to be predetermined and require direct human reprogramming to change them.
Such databases are adequate as long as the data is reasonably long lasting and can be maintained within a constant format. But, if there are any chaotic or unpredictable elements of change, there will be problems because it will be extremely difficult to arrange for the database to question the validity of data, anticipate the possibility of error or check that it has become redundant or is incomplete.
Many important categories of information and knowledge – such as the expanding and evolving areas of technology – have such a high level of unpredictable volatility that reliable output is prohibitively expensive to maintain. The databases quickly become choked with redundant and conflicting information, the efficiency soon declining to a point where the information that is retrieved has very little practical value. This is the problem confronting anyone who would want to create the kind of database that Tillman Pearce is looking for.
In these situations, when accurate information and knowledge is not readily available, people resort to the age old custom of asking around: finding somebody who may have the information they need. This involves a bottom up strategy – following a trail, routed through person to person contact, with one piece of information leading to the discovery of another until the information or the solution to a problem is found.
In pre Internet days, the telephone was perfectly adequate for this kind of strategy. Databases could take the form of directories, yellow pages, etceteras – that listed contact names – where bottom up, seek to find strategies could begin a search for people who might point to any kind of ill defined, fuzzy or elusive types of information that might be needed.
Such a strategy is illustrated in a generic form in figure 9.2.
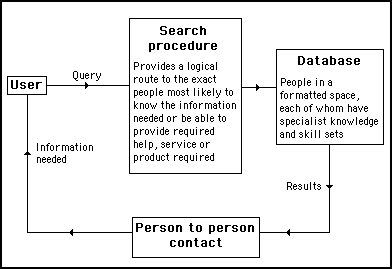
Figure 9.2
A strategy to find ill defined, fuzzy or elusive types of information must involve asking people. A system needs to be devised to locate the appropriate people to ask
Figure 9.2 shows how it is necessary to have some method of formatting the space where people can be found and a procedure for finding the most suitable people to provide any required information. In pre Internet times the database would be a directory of names, separated into various categories. The search procedure would involve nothing more complicated than choosing people in an appropriate category to question.
Viewed in the diagrammatic form, it becomes obvious that in the massive communication environment of the Internet and with the rapidly changing and evolving nature of knowledge and information, similar problems will occur as with a conventional database.
The number of people needing to be included in the people space would be impossibly large. There would be too many categories and the categories chosen would have to be constantly changed and added to. There would be too many ways in which the people space can be formatted. Even for the people that could be listed and categorised, there would be no certainty that they could provide currently accurate or up to date information. There would be no precise way of determining who knew what and the extent and exact nature of their knowledge.
With these thoughts in mind, let's turn to the opportunity offered by the problem of creating a treatment database for cancer patients as outlined by Tillman Pearce.