Understanding complexity
Theories usually explain how things work. They provide conceptual models, backed up by mathematical or logical reasoning. In most cases, theories allow you to model a situation so that you can make predictions as to what will happen under certain conditions. In other words, theories provide a tool for you to be able to predict outcomes.
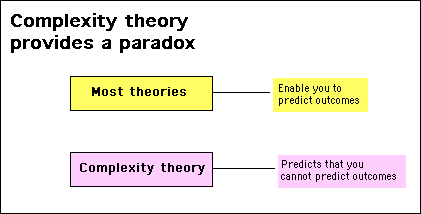
Theories about complexity are different. They do not explain how things work or allow you to make predictions.
Most people get confused when they encounter complexity theories because although they provide conceptual models with plenty of mathematics to support them, the conceptual models are useless for purposes of prediction or determining outcomes. In fact, the main message complexity theory provides is that it is virtually impossible to work out how a complex system will behave.
You might wonder what use a theory might be, if it has no power of prediction. This thought is the reason why complexity theory is so often misunderstood and, as a consequence, ignored as a useful tool.
To understand the usefulness and power of complexity theory, you need to understand a paradox: complexity theory does make a prediction: it predicts that you cannot predict what a complex system will do. It is only when this thought sinks in you can begin to discover ways to control dynamic systems.
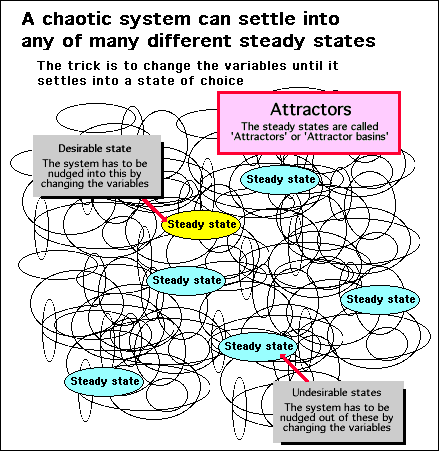
Dynamic complex systems, fractals and other non predictable phenomenon have one thing in common: they contain non-linearities, phase transitions and sudden unpredictable changes. A disturbed complex system can act chaotically, wildly fluctuating in its behavior. However, this is usually only a temporary transitional state because, sooner or later, they usually settle down into a steady state where their performance is constant.
What computer simulations of complex systems have revealed is that complex systems do not have a single steady state, but have a multitude of possible steady states that the system can take up depending upon the values of critical variables.
You may not be able to predict which particular steady state a system might take up when you change the variables, but you do know that it will settle into one or other of them if it is disturbed or changed in some way. The diagram below illustrates this situation.
The key to understanding
Knowing a dynamic system can have many different steady states is the key to understanding the usefulness of chaos theory. It isn't about considering the fluctuations of the chaotic state. The trick is in being able to guide a dynamic system into settling into a particular steady state that suits your purpose.
The correct mind set is to think of a complex system not as something you have to pre-design, but as a system you have to guide into doing what you want it to do. You have to keep nudging it around until it behaves in a satisfactory way.
You can liken this to training a dog to fetch a thrown stick. The dog can display any kind of behavior when you throw a stick, but, by suitably rewarding the dog - when it runs in the direction of the stick, when it picks it up and again when it brings the stick back to you - you are in fact controlling the behavior of an unpredictable, complex system.
Improvement through disturbances
Once you begin to understand that a system can be controlled by changing the variables until it settles into a satisfactory state of operation, you are then faced with the problem of what variables to change and how they should be changed. This can involve an almost infinite number of combinations and possibilities. However, nature has solved this problem using an evolutionary strategy.
The way nature uses an evolutionary strategy to solve this problem was discovered in the 1980's by John Holland. He devised a computer model to emulate this process. Known as a genetic algorithm, variations of this program are now used in a wide variety of different areas to solve the problem of finding the optimum values of variables in all kinds of dynamic systems.
Although this can be thought of as simply a 'trial and error' approach, the way it works is to quickly identify the most influential variables in a system; get these right; then proceed to the next most important variable to get those right. The algorithm keeps working through all the system variables in this way, setting their values in a sequence according to their influence on the system.
This is the procedure Nature adopts in her evolutionary strategy. The advantage is that if a system is changed or disturbed through some unpredictable occurrence, this strategy can quickly re-configure the system variables to get it working efficiently again. More importantly, it can change the variables in such a way that it can take advantage of the changing situation to make the system work more efficiently than it did before. This is how natural systems can evolve to become increasingly organized and efficient. They welcome change because it can lead to improvements.
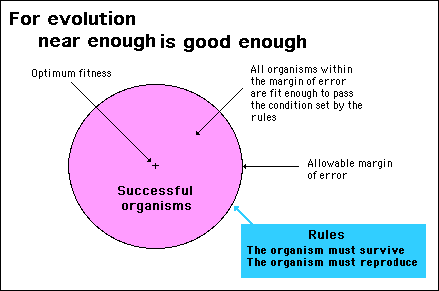
Near enough is good enough
Genetic algorithms are believed by most scientists to be the mathematical proof that underwrites the theory of evolution. But not everyone agrees. Paradoxically, it is by looking at the argument of the people who disagree that you can understand how they work in an evolutionary strategy.
The basic premise of a genetic algorithm is that it "randomly tries out different values of the variables involved in a solution to gradually arrive at optimum values". If you miss the significance of giving preference to the most influential variables, it can seem to be a vague 'hit of miss' strategy.
There are several versions of what is called the "Free Lunch Theory" that proves conclusively that genetic algorithms are nothing special: as "the performance of any algorithm averaged over all possible cost functions will be the same as that of any other algorithm". This view is particularly championed by William A. Dembski in his book "No Free Lunch", where he states "evolutionary algorithms are incapable of providing a computational justification for the Darwinian mechanism of natural selection and random variation as the primary creative force in biology".
However, what the proponents of this view don't seem to take into consideration is that the evolutionary process doesn't have to search for an exact solution: near enough is good enough (see diagram below). In other words, evolution doesn't seek to find the optimum solution for fitness, it needs only to find a solution that is near enough in order to achieve a particular objective. In the case of evolution this is enough fitness to be able to survive and reproduce. In other words, it can stop searching once the most important variable values has been determined.
This is important because although genetic algorithms are not any more efficient than any other search algorithms at finding exact optimum solutions, they are far more efficient at getting a solution that is near enough. In this context, genetic algorithms do provide the mathematical proof that underpins the theory of evolution.
For this reason we can use the technique of evolution - which is to try out different values of the variables of a system - until a 'near enough' solution is found.